문자열 인코딩
인코딩이란 특정한 목적을 위해 정보의 형태를 변환하는 것을 의미한다. 즉 문자열 인코딩이란 컴퓨터가 이해 할 수 있는 정보의 형태로(0과 1로만 이루어진 바이너리 데이터) 문자열을 변환하는 것이다.
문자집합
각각의 문자를 숫자에 대응시킨 표, ASCII, ANSI, UNICODE 등이 있다.
-
ASCII
미국에서 정의한 표준 부호체계, 영문 키보드로 입력이 가능한 모든 기호를 할당할 수 있다. 컴퓨터의 가장 기본 저장 단위인 1byte 중 7bit는 문자 할당을 위해 사용하고, 나머지 1bit(Parity Bit)는 통신에러 검출을 위해 사용한다.
-
ANSI
ASCII에서 Parity Bit로 쓰이던 1bit를 문자열 할당에 사용한다. 8Bit를 모두 사용하기 때문에 총 256가지의 문자에 대응될 수 있다. 하지만 여전히 다른 나라의 문자까지 표현하기에는 턱없이 부족하다.
-
UNICODE
전 세계의 모든 문자를 다룰 수 있도록 설계된 표준 문자코드표 우리가 흔히 접하는 UTF-8은 유니코드를 인코딩하는 하나의 방식이다. 유니코드는 평면 이라고 하는 세부 영역으로 나누어져 있다.
-
EUC-KR, CP949
이전에는 각 나라마다 독립적인 인코딩 방식을 만들어 사용했었고, 한국에서는 EUC-KR이라는 인코딩 방식을 만들었다. EUC-KR은 현대 한글에서 자주 이용되는 2350개의 글자만 지원 했기 때문에, 일부 한글을 표현 할 수 없는 문제점이 있었다. 이런 문제점을 해결하기 위해 마이크로 소프트사에서 기존의 EUC-KR을 확장한 CP949를 만들었다. 하지만 CP949는 코드값이 앞선 것이 사전순으로도 앞선다는 것을 보장하지 않는다. 때문에 코드 값을 이용한 사전순 정렬이 불가능하다. CMD 윈도우 명령 프롬프트의 기본 인코딩이 CP949이다.
UTF-8
1~4바이트 가변 길이 인코딩, 8비트 단위로 인코딩 하기 때문에 ASCII와 호환된다. 사실상 표준 인코딩 방식이다.
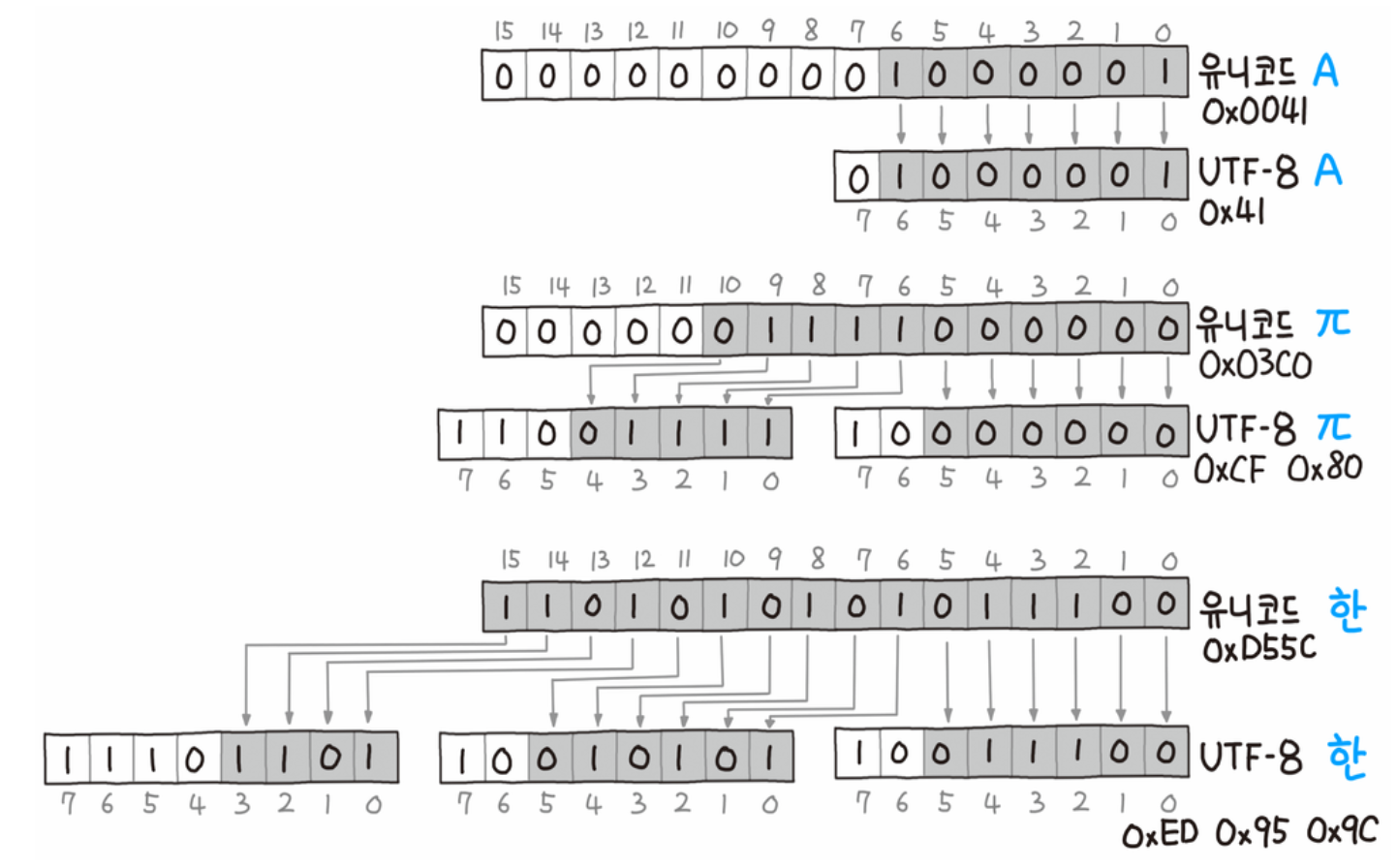
문자 ‘한’이 유니코드에 대응되는 코드값은 1101010101011100 (0xD55C)이지만,
UTF-8로 인코딩 하면 11101101 10010101 10011100 (0xED 0x95 0x9c)으로 3Byte 가 된다.
가변 길이 정보
위 사진에서 ‘한’이 인코딩 될 때, 본래 ‘한’의 코드값을 1101 010101 011100으로 자른뒤, 이 값을 미리 준비해둔 1110xxxx 10xxxxxx 10xxxxxx의 형태에 대입하는 것을 알 수 있다.
이런 과정을 거치는 것은 UTF-8이 가변 길이 문자 인코딩이기 때문에 규칙을 정하지 않는다면(길이 정보가 없다면), 제대로 디코딩을 할 수 없기 때문이다.
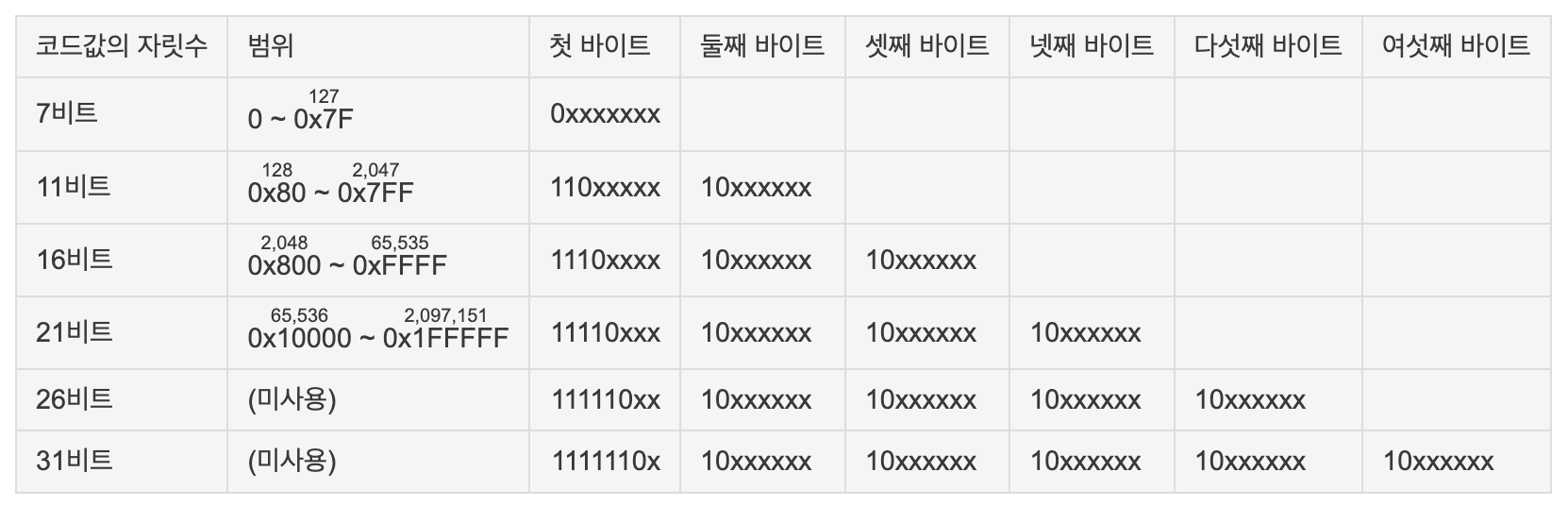
첫 바이트의 1110 은 해당 문자가 3바이트 임을 의미한다. 맨 앞의 1은 1바이트를 초과함을 의미하고, 뒤의 11은 후속바이트가 2개라는 것을 의미한다.
두 번째, 세 번째 바이트의 앞에 있는 10은 해당 바이트가 독립된 문자가 아닌 후속 바이트임을 나타낸다.
UTF-16, UTF-32 ?
이름에서 알 수 있듯이, 각각 16비트, 32비트 단위로 인코딩하는 방식이다.
UTF-16 : 한글과 한자를 모두 2바이트로 표현 할 수 있기 때문에, 한글을 다룰 때는 UTF-8 보다 크기가 조금 줄어든다는 이점이 있다.
UTF-32 : ‘모든’ 문자를 4바이트로 표현한다. 따라서 고정된 크기로 모든 문자를 표현 할 수 있지만, 저장 공간 낭비가 심하다는 단점이 있다.
Java 에서 char 타입 변수에 한글을 저장해도 깨지지 않는 이유
char a = '한';
System.out.println(a) // `한` 이 정상적으로 출력된다.
JVM은 문자열을 다룰 때 UTF-16 방식으로 인코딩 하기 때문에, 위와 같이 char 타입에 한글을 2Byte로 저장 할 수 있다.
Java가 UTF-16을 선택한 이유
는 다양한 문자를 다루는 환경에서는 UTF-16을 사용하는게 더 효율적이기 때문이다.
utf8mb4 ?
MySQL의 character set을 보면 utf8mb4 라는 녀석이 있다. 전세계의 모든 언어는 21비트 내에서 표현이 가능하기 때문에, MySQL에서는 utf8을 3바이트 기반 가변 자료형으로 설계를 해뒀었다. 하지만 이로인해 4바이트 문자열(이모티콘)을 저장 할 수 없는 문제가 있었고, 이를 해결하기 위해 MySQL 5.5버전 이후부터 utf8mb4 이 추가되었다.
Base64
플랫폼 독립적으로(문자 집합의 영향을 받지 않고) 바이너리 데이터(이미지, 오디오, 실행파일 등)가 전송, 저장 되는것을 보장하기위해 사용하는 인코딩 방식
ASCII 문자중 제어 문자와 일부 특수문자를 제외한 64개의 문자만을 사용한다.
.png)
e.g. 인코딩 방식
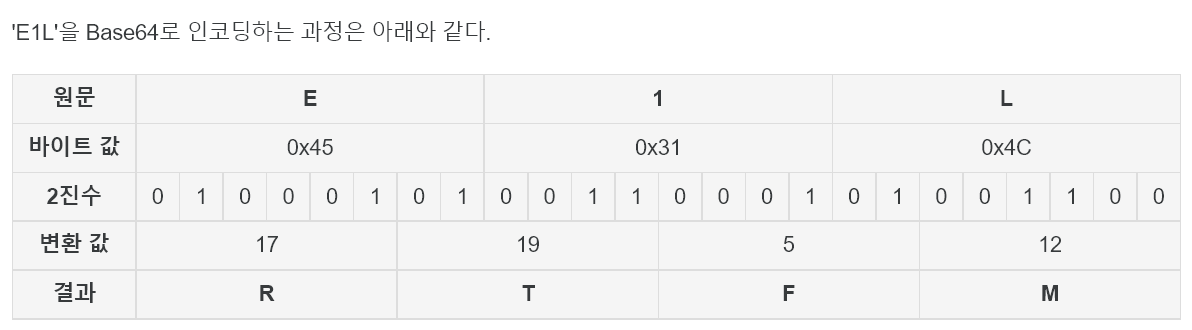
3바이트(24비트)를 6비트씩 4개로 쪼개서 Base64 코드 4개로 표현한다.
바이너리 파일?
바이너리 파일은 텍스트 파일을 제외한 모든 파일을 의미한다. 바이너리 파일에는 디코드 방법에대한 정보(몇 바이트씩 잘라야 하는지)가 없기 때문에, 알맞는 프로그램을 통해서만 온전한 데이터를 확인 할 수 있다. 예를 들어 사진 파일을 메모장으로 열게되면, 의미를 알 수 없는 문자들이 표시된다.
댓글남기기